
Unix Domain Socket源码实现分析(OLK 6.6)
对于正常的uds通信的创建一般分为两个部分:server和client,我们分别从server和client构建代码的关键函数来分析uds的源码实现
server实现代码:
// Server code (server.c)
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define SOCKET_PATH "unix_socket"
#define BUFFER_SIZE 100
int main() {
int server_sock, client_sock;
struct sockaddr_un server_addr;
char buffer[BUFFER_SIZE];
// Create socket
if ((server_sock = socket(AF_UNIX, SOCK_STREAM, 0)) == -1) {
perror("socket error");
exit(1);
}
// Set server address structure
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sun_family = AF_UNIX;
strncpy(server_addr.sun_path, SOCKET_PATH, sizeof(server_addr.sun_path) - 1);
// Bind the socket to the address
unlink(SOCKET_PATH);
if (bind(server_sock, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("bind error");
close(server_sock);
exit(1);
}
// Listen for incoming connections
if (listen(server_sock, 5) == -1) {
perror("listen error");
close(server_sock);
exit(1);
}
printf("Server is listening on %s\n", SOCKET_PATH);
// Accept a client connection
if ((client_sock = accept(server_sock, NULL, NULL)) == -1) {
perror("accept error");
close(server_sock);
exit(1);
}
// Receive data from the client
int bytes_received = read(client_sock, buffer, BUFFER_SIZE);
if (bytes_received > 0) {
buffer[bytes_received] = '\0';
printf("Received from client: %s\n", buffer);
}
// Send a response to the client
const char* response = "Message received";
write(client_sock, response, strlen(response));
// Clean up
close(client_sock);
close(server_sock);
unlink(SOCKET_PATH);
return 0;
}
client实现代码:
// Client code (client.c)
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define SOCKET_PATH "unix_socket"
int main() {
int client_sock;
struct sockaddr_un server_addr;
// Create socket
if ((client_sock = socket(AF_UNIX, SOCK_STREAM, 0)) == -1) {
perror("socket error");
exit(1);
}
// Set server address structure
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sun_family = AF_UNIX;
strncpy(server_addr.sun_path, SOCKET_PATH, sizeof(server_addr.sun_path) - 1);
// Connect to the server
if (connect(client_sock, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("connect error");
close(client_sock);
exit(1);
}
// Send data to the server
const char* message = "Hello, server!";
write(client_sock, message, strlen(message));
// Receive response from the server
char buffer[100];
int bytes_received = read(client_sock, buffer, sizeof(buffer) - 1);
if (bytes_received > 0) {
buffer[bytes_received] = '\0';
printf("Received from server: %s\n", buffer);
}
// Clean up
close(client_sock);
return 0;
}
通信流程如下:
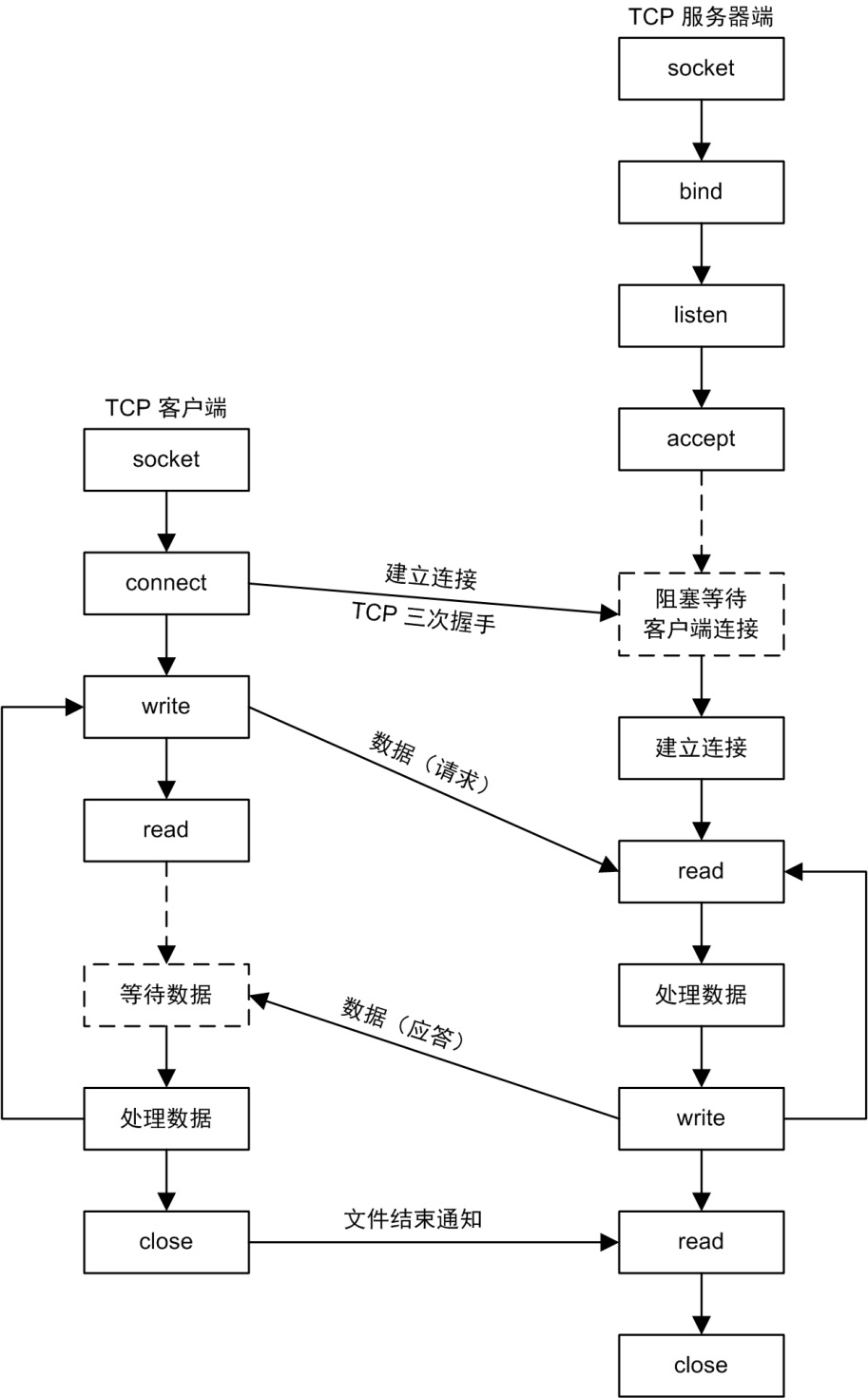
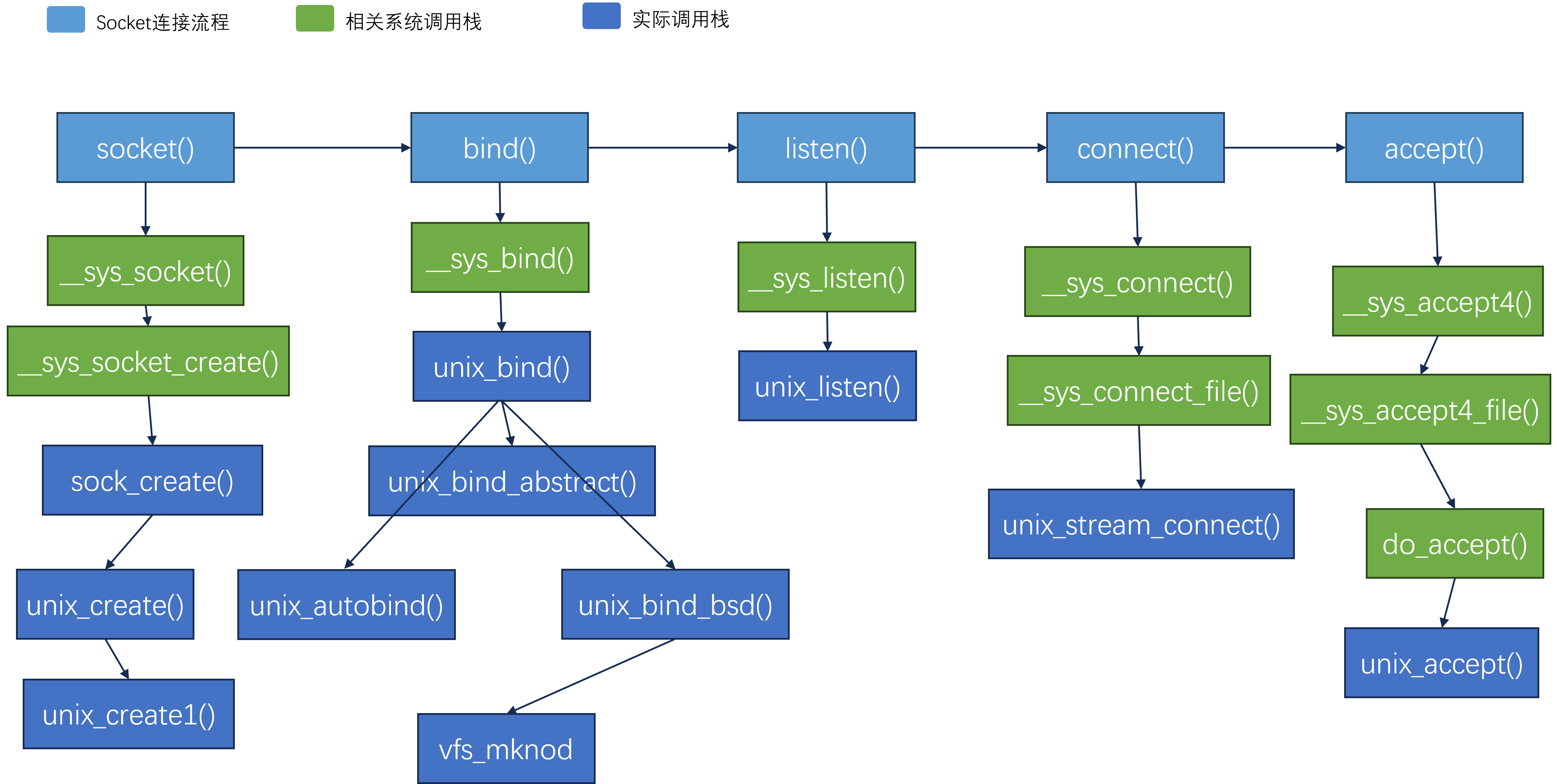
源码分析结构图如下:
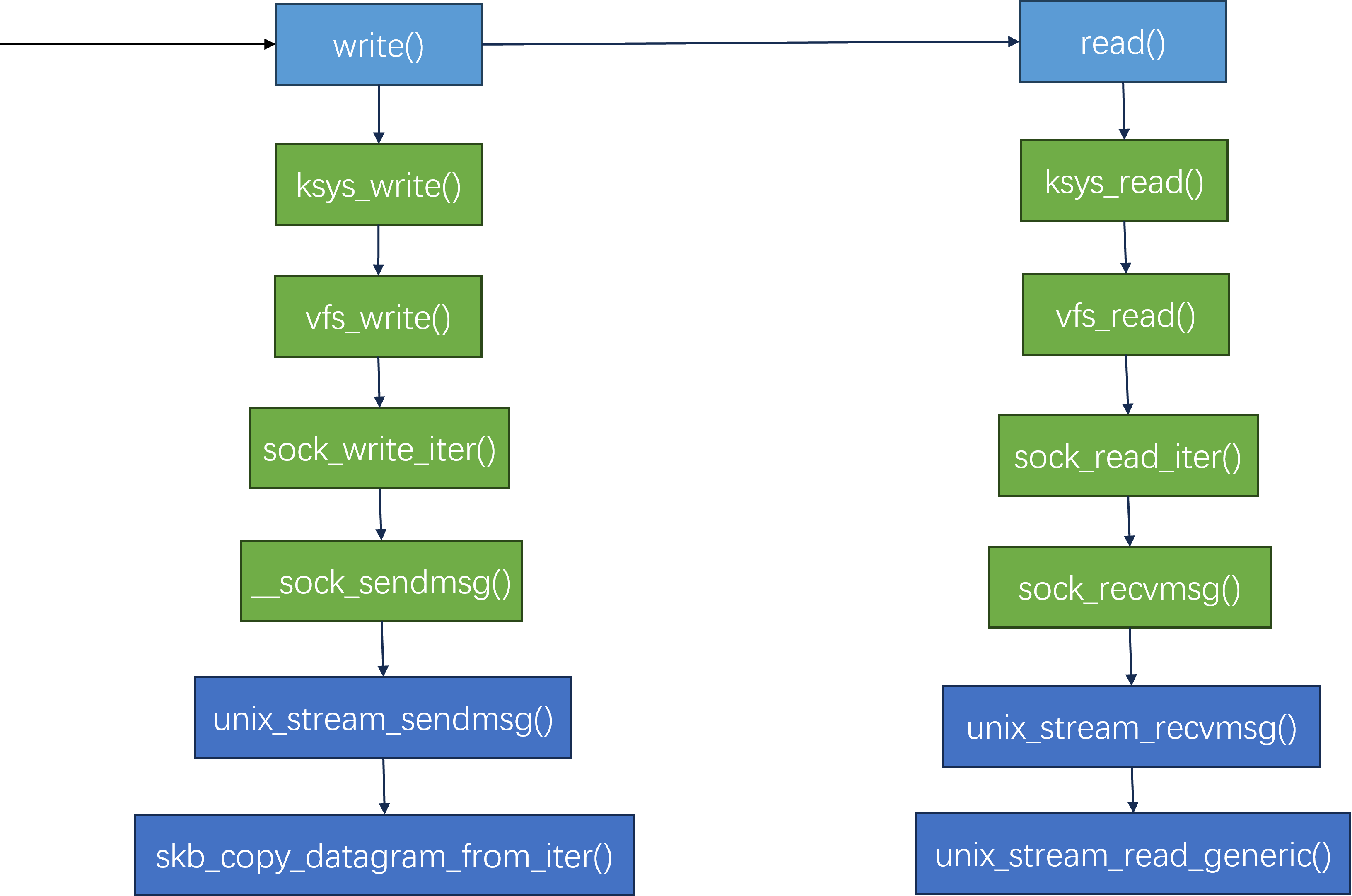
unix域套接字地址结构
//include/uapi/linux/un.h
#define UNIX_PATH_MAX 108
struct sockaddr_un {
__kernel_sa_family_t sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* pathname */
};
socket()
一句话概括socket函数:创建并初始化套接字,创建文件描述符并关联。
//syscall系统调用
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
return __sys_socket(family, type, protocol);
}
socket()->__sys_socket()
//__sys_socket通过调用__sys_socket_create函数返回sock对象,最后通过sock_map_fd函数将对象转化为文件描述符。
int __sys_socket(int family, int type, int protocol)
{
struct socket *sock;
int flags;
sock = __sys_socket_create(family, type,
update_socket_protocol(family, type, protocol));
if (IS_ERR(sock))
return PTR_ERR(sock);
flags = type & ~SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
套接字的创建由__sys_socket_create完成,sock_map_fd分配一个文件描述符,然后为套接字分配文件对象,最后将两者关联起来。
sock_map_fd()将sock结构映射为文件描述符
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
//获取可用文件描述符
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0)) {
sock_release(sock);
return fd;
}
//调用 sock_alloc_file() 为套接字分配一个文件对象 (struct file)。
newfile = sock_alloc_file(sock, flags, NULL);
//如果分配成功,调用 fd_install(fd, newfile) 将文件对象与文件描述符 (fd) 关联起来,并返回该文件描述符。
if (!IS_ERR(newfile)) {
fd_install(fd, newfile);
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
sock_map_fd()->sock_alloc_file()
struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname)
{
struct file *file;
if (!dname)
dname = sock->sk ? sock->sk->sk_prot_creator->name : "";
//分配伪文件 (alloc_file_pseudo):
file = alloc_file_pseudo(SOCK_INODE(sock), sock_mnt, dname,
O_RDWR | (flags & O_NONBLOCK),
&socket_file_ops);
if (IS_ERR(file)) {
sock_release(sock);
return file;
}
//文件对象初始化
file->f_mode |= FMODE_NOWAIT;
sock->file = file;
file->private_data = sock;
stream_open(SOCK_INODE(sock), file);
return file;
}
EXPORT_SYMBOL(sock_alloc_file);
__sys_socket()->__sys_socket_create()
//__sys_socket_create调用sock_create创建socket
static struct socket *__sys_socket_create(int family, int type, int protocol)
{
struct socket *sock;
int retval;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
if ((type & ~SOCK_TYPE_MASK) & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return ERR_PTR(-EINVAL);
type &= SOCK_TYPE_MASK;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return ERR_PTR(retval);
return sock;
}
__sys_socket_create()->sock_create()
//sock_create调用__sock_create
/**
* sock_create - creates a socket
* @family: protocol family (AF_INET, ...)
* @type: communication type (SOCK_STREAM, ...)
* @protocol: protocol (0, ...)
* @res: new socket
*
* A wrapper around __sock_create().
* Returns 0 or an error. This function internally uses GFP_KERNEL.
*/
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
//EXPORT_SYMBOL() 是一个内核宏,用于将符号(函数或变量)导出到内核的符号表中,以便该函数可以被其他内核模块使用。
EXPORT_SYMBOL(sock_create);
__sock_create->unix_create()
/**
* __sock_create - creates a socket
* @net: net namespace
* @family: protocol family (AF_INET, ...)
* @type: communication type (SOCK_STREAM, ...)
* @protocol: protocol (0, ...)
* @res: new socket
* @kern: boolean for kernel space sockets
*
* Creates a new socket and assigns it to @res, passing through LSM.
* Returns 0 or an error. On failure @res is set to %NULL. @kern must
* be set to true if the socket resides in kernel space.
* This function internally uses GFP_KERNEL.
*/
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
...
//Check if creating a new socket is allowed
err = security_socket_create(family, type, protocol, kern);
/*
* Allocate the socket and allow the family to set things up. if
* the protocol is 0, the family is instructed to select an appropriate
* default.
*/
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited("socket: no more sockets\n");
return -ENFILE; /* Not exactly a match, but its the
closest posix thing */
}
...
pf = rcu_dereference(net_families[family]);
/*
* We will call the ->create function, that possibly is in a loadable
* module, so we have to bump that loadable module refcnt first.
*/
err = pf->create(net, sock, protocol, kern);
...
EXPORT_SYMBOL(__sock_create);
sock_create()函数首先调用security_socket_create检查是否有权限创建新的socket文件,接着调用sock_alloc()申请一个struct socket结构,然后调用指定协议族的create()函数(net_families[family]->create())进行进一步的创建功能。net_families变量的类型为struct net_proto_family,其定义如下:
struct net_proto_family {
int family;
int (*create)(struct socket *sock, int protocol);
...
};
family字段对应的就是具体的协议族,而create字段指定了其创建socket的方法。一个具体协议族需要通过调用sock_register()函数向系统注册其创建socket的方法。例如Unix socket就在初始化时通过下面的代码注册:
static const struct net_proto_family unix_family_ops = {
.family = PF_UNIX,
.create = unix_create,
.owner = THIS_MODULE,
};
static int __init af_unix_init(void)
{
...
sock_register(&unix_family_ops);
...
return 0;
}
所以从上面的代码可以指定,对于
Unix socket的话,net_families[family]->create()这行代码实际调用的是unix_create()函数。
//unix_create初始化套接字并根据类型调用合适的处理函数,同时调用unix_create1函数创建socket。
static int unix_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
//将套接字状态设置为未连接。
sock->state = SS_UNCONNECTED;
//根据套接字类型设置操作:
switch (sock->type) {
case SOCK_STREAM:
sock->ops = &unix_stream_ops;
break;
/*
* Believe it or not BSD has AF_UNIX, SOCK_RAW though
* nothing uses it.
*/
case SOCK_RAW:
sock->type = SOCK_DGRAM;
fallthrough;
case SOCK_DGRAM:
sock->ops = &unix_dgram_ops;
break;
case SOCK_SEQPACKET:
sock->ops = &unix_seqpacket_ops;
break;
default:
return -ESOCKTNOSUPPORT;
}
sk = unix_create1(net, sock, kern, sock->type);
if (IS_ERR(sk))
return PTR_ERR(sk);
return 0;
}
unix_create()->unix_create1()
//分配资源和初始化各种内部数据结构。
static struct sock *unix_create1(struct net *net, struct socket *sock, int kern, int type)
{
struct unix_sock *u;
struct sock *sk;
int err;
...
//根据套接字类型 (SOCK_STREAM, SOCK_DGRAM 或 SOCK_SEQPACKET),调用 sk_alloc() 分配一个新的 sock 对象。
if (type == SOCK_STREAM)
sk = sk_alloc(net, PF_UNIX, GFP_KERNEL, &unix_stream_proto, kern);
else /*dgram and seqpacket */
sk = sk_alloc(net, PF_UNIX, GFP_KERNEL, &unix_dgram_proto, kern);
...
//将套接字 sock 与sock对象 sk 相关联,初始化数据结构。
sock_init_data(sock, sk);
//初始化 sk 结构的成员
sk->sk_hash = unix_unbound_hash(sk);
sk->sk_allocation = GFP_KERNEL_ACCOUNT;
sk->sk_write_space = unix_write_space;
sk->sk_max_ack_backlog = net->unx.sysctl_max_dgram_qlen;
sk->sk_destruct = unix_sock_destructor;
u = unix_sk(sk);
u->path.dentry = NULL;
u->path.mnt = NULL;
...
return sk;
struct socket 是 Linux 网络栈中表示一个套接字的核心结构,通常用于与用户空间应用程序进行交互。sock 是用户空间程序与内核中的网络栈通信的接口,代表了一个网络端点,用于建立连接、发送/接收数据等操作
unix_sock 是一个在 Linux 内核中与 Unix 域套接字相关的私有数据结构。它扩展了 struct sock,用于存储与 Unix 域套接字相关的特定数据。
bind()
一句话概括bind函数:将uds地址绑定到套接字
//syscall系统调用
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
return __sys_bind(fd, umyaddr, addrlen);
}
bind()->__sys_bind()
int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
//查找套接字
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
//将用户空间地址移动到内核空间
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (!err) {
//安全检查(权限)
err = security_socket_bind(sock,
(struct sockaddr *)&address,
addrlen);
if (!err)
//执行具体协议实现的bind函数
err = READ_ONCE(sock->ops)->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
__sys_bind()->unix_bind()
static int unix_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_un *sunaddr = (struct sockaddr_un *)uaddr; // 将通用地址结构转换为UNIX专用的地址结构
struct sock *sk = sock->sk; // 获取套接字的基础结构
int err; // 用于存储错误码
// 当 sun_path 为空时,unix_autobind() 会为套接字自动生成一个唯一的、临时的地址,通常在内核中创建一个临时文件来表示该套接字的地址。
if (addr_len == offsetof(struct sockaddr_un, sun_path) &&
sunaddr->sun_family == AF_UNIX)
return unix_autobind(sk);
// 验证地址是否合法
err = unix_validate_addr(sunaddr, addr_len);
if (err)
return err;
// 根据sun_path的第一个字符决定调用哪个绑定函数
if (sunaddr->sun_path[0])
err = unix_bind_bsd(sk, sunaddr, addr_len); // 调用BSD风格地址绑定函数
else
err = unix_bind_abstract(sk, sunaddr, addr_len); // 调用抽象地址绑定函数
return err;
}
这里涉及到了三种不同的bind函数调用,自动绑定(
unix_autobind)、BSD 风格 (unix_bind_bsd()) 和抽象风格 (unix_bind_abstract())
- BSD 风格绑定 (
unix_bind_bsd())- 路径地址绑定:BSD 风格的 UNIX domain socket 使用文件系统中的路径作为地址。例如:
/tmp/mysocket,即sun_path的第一个字符是/,表示它是一个标准的路径。 - 文件系统依赖:BSD 风格的地址实际上是文件系统中的一个路径,因此它需要在文件系统中创建一个对应的文件节点,这样其他进程就可以通过访问这个文件节点来与该套接字通信。
- 持久性:由于是基于文件系统的路径,BSD 风格的 UNIX socket 地址在程序退出后文件仍然存在,因此需要显式地删除路径(即使用
unlink()),否则下次绑定同样的路径可能会失败。
- 路径地址绑定:BSD 风格的 UNIX domain socket 使用文件系统中的路径作为地址。例如:
- 抽象风格绑定 (
unix_bind_abstract())- 不依赖于文件系统:抽象风格的 UNIX domain socket 地址不是基于文件系统的路径,而是由一个以
NUL(空字符,'\0')开头的字符串作为地址。因为这个地址不是文件路径,所以它不依赖文件系统,适合在某些情况下避免文件系统的复杂性或开销。 - 仅在内核中存在:抽象地址的作用域仅限于内核内部,它不需要在文件系统中创建节点,因此完全由内核管理。这样可以减少对磁盘的依赖,同时在某些系统(如没有持久存储的嵌入式系统)中也很有用。
- 临时性:抽象地址的生命周期与绑定该地址的进程的生命周期相同,当进程结束时,抽象地址也随之释放。它不需要像 BSD 风格那样手动删除路径。
- 不依赖于文件系统:抽象风格的 UNIX domain socket 地址不是基于文件系统的路径,而是由一个以
BSD 风格提供了一种基于文件系统的地址绑定方式,具有持久性和文件权限管理的优点,适合需要长期通信和文件权限控制的应用场景。
抽象风格则提供了一种内核管理的轻量化地址绑定方式,避免了文件系统的依赖,更适合临时性通信,减少了资源占用和管理开销。
第一种:unix_bind()->unix_autobind()
unix_autobind()是一个用于自动为套接字分配地址的函数,适用于 UNIX domain socket 没有提供具体绑定地址的情况。当用户调用bind()但是没有指定地址时,unix_autobind()会被调用,它会为套接字生成一个唯一的、临时的抽象地址。
static int unix_autobind(struct sock *sk)
{
unsigned int new_hash, old_hash = sk->sk_hash;
struct unix_sock *u = unix_sk(sk);
struct net *net = sock_net(sk);
struct unix_address *addr;
u32 lastnum, ordernum; //ordernum 和 lastnum:用于生成唯一的抽象地址。
int err;
err = mutex_lock_interruptible(&u->bindlock);
if (err)
return err;
if (u->addr)
goto out;
err = -ENOMEM;
// 使用 kzalloc() 为 unix_address 结构分配内存,包含了地址结构和 sun_path 的存储空间。如果内存分配失败,返回 -ENOMEM。使用 kzalloc() 为 unix_address 结构分配内存,包含了地址结构和 sun_path 的存储空间。如果内存分配失败,返回 -ENOMEM。
addr = kzalloc(sizeof(*addr) +
offsetof(struct sockaddr_un, sun_path) + 16, GFP_KERNEL);
if (!addr)
goto out;
addr->len = offsetof(struct sockaddr_un, sun_path) + 6;
addr->name->sun_family = AF_UNIX;
refcount_set(&addr->refcnt, 1);
// 使用 get_random_u32() 获取一个随机数,用于生成唯一的抽象地址。
ordernum = get_random_u32();
// lastnum 保存了随机数的低 20 位,用于限制循环次数,确保不会无限循环。
lastnum = ordernum & 0xFFFFF;
retry: // 生成和检查地址唯一性 (retry):
ordernum = (ordernum + 1) & 0xFFFFF;
sprintf(addr->name->sun_path + 1, "%05x", ordernum);
new_hash = unix_abstract_hash(addr->name, addr->len, sk->sk_type);
unix_table_double_lock(net, old_hash, new_hash);
// 检查地址是否已存在
if (__unix_find_socket_byname(net, addr->name, addr->len, new_hash)) {
unix_table_double_unlock(net, old_hash, new_hash);
/* __unix_find_socket_byname() may take long time if many names
* are already in use.
*/
//如果地址已存在,解锁哈希表,并调用 cond_resched() 让出 CPU 资源,然后继续生成新的地址(跳转到 retry 标签)。如果所有地址都已用尽,返回 -ENOSPC,表示没有空间可用。
cond_resched();
if (ordernum == lastnum) {
/* Give up if all names seems to be in use. */
err = -ENOSPC;
unix_release_addr(addr);
goto out;
}
goto retry;
}
// __unix_set_addr_hash() 将生成的地址设置到套接字中,并更新哈希表。
__unix_set_addr_hash(net, sk, addr, new_hash);
unix_table_double_unlock(net, old_hash, new_hash);
err = 0;
out: mutex_unlock(&u->bindlock);
return err;
}
第二种:unix_bind()->unix_bind_abstract()
unix_bind_abstract()是一个用于将 UNIX domain socket 地址绑定到套接字的内核函数,专门用于抽象风格地址(即不依赖于文件系统的地址)。这个函数负责确保套接字被绑定到一个唯一的抽象地址,并对地址进行哈希和注册处理。以下是对该函数的详细分析。
static int unix_bind_abstract(struct sock *sk, struct sockaddr_un *sunaddr,
int addr_len)
{
unsigned int new_hash, old_hash = sk->sk_hash;
struct unix_sock *u = unix_sk(sk);
struct net *net = sock_net(sk);
struct unix_address *addr;
int err;
// 创建UNIX地址,为抽象地址分配内存,并将用户提供的地址数据(sunaddr)转换为内核使用的地址结构。
addr = unix_create_addr(sunaddr, addr_len);
//使用 unix_abstract_hash() 计算新地址的哈希值,用于将抽象地址放入内核中的哈希表进行管理。
new_hash = unix_abstract_hash(addr->name, addr->len, sk->sk_type);
//__unix_set_addr_hash() 设置新的绑定地址,并将其插入哈希表中,以便后续可以通过地址快速找到对应的套接字。
__unix_set_addr_hash(net, sk, addr, new_hash);
return 0;
}
第三种:unix_bind()->unix_bind_bsd()
unix_bind_bsd()是内核中用于将 BSD 风格的 UNIX domain socket 地址绑定到套接字的函数。它实现了将套接字地址绑定到文件系统路径的逻辑,并确保地址唯一性和相应的文件系统操作。以下是对这个函数的详细分析。
static int unix_bind_bsd(struct sock *sk, struct sockaddr_un *sunaddr,
int addr_len)
{
umode_t mode = S_IFSOCK | // 设置文件模式为套接字
(SOCK_INODE(sk->sk_socket)->i_mode & ~current_umask()); // 根据套接字的模式和当前掩码计算文件模式
unsigned int new_hash, old_hash = sk->sk_hash; // 新旧哈希值
struct unix_sock *u = unix_sk(sk); // 获取UNIX套接字结构体
struct net *net = sock_net(sk); // 获取套接字关联的网络命名空间
struct mnt_idmap *idmap; // ID映射
struct unix_address *addr; // UNIX地址结构
struct dentry *dentry; // 目录项
struct path parent; // 父目录路径
int err; // 错误码
// 对传入的地址进行处理,确保其格式正确,并计算所需的地址长度。
addr_len = unix_mkname_bsd(sunaddr, addr_len);
// unix_create_addr():为套接字地址分配内存,将传入的地址数据存储在新创建的 unix_address 结构中。如果分配失败,返回 -ENOMEM。
addr = unix_create_addr(sunaddr, addr_len);
if (!addr)
return -ENOMEM; // 内存分配失败
// kern_path_create():查找或创建对应路径的目录项 (dentry),获取地址所在路径的父目录 (parent)。
dentry = kern_path_create(AT_FDCWD, addr->name->sun_path, &parent, 0);
if (IS_ERR(dentry)) { // 处理错误
err = PTR_ERR(dentry);
goto out;
}
// 在文件系统中创建套接字节点
idmap = mnt_idmap(parent.mnt); // 获取ID映射
err = security_path_mknod(&parent, dentry, mode, 0); // 首先进行安全检查,确保当前进程有权限在指定路径创建节点。
if (!err)
err = vfs_mknod(idmap, d_inode(parent.dentry), dentry, mode, 0); // 在文件系统中创建节点,用于表示该 UNIX domain socket。
err = mutex_lock_interruptible(&u->bindlock); // 锁定互斥量
new_hash = unix_bsd_hash(d_backing_inode(dentry)); // 创建哈希值
unix_table_double_lock(net, old_hash, new_hash); // 锁定双向哈希表
u->path.mnt = mntget(parent.mnt); // 设置路径
u->path.dentry = dget(dentry); // 设置目录项
__unix_set_addr_hash(net, sk, addr, new_hash); // 设置地址哈希
unix_table_double_unlock(net, old_hash, new_hash); // 解锁双向哈希表
unix_insert_bsd_socket(sk); // unix_insert_bsd_socket():将该套接字插入到 BSD 风格套接字的管理结构中。
mutex_unlock(&u->bindlock); // 解锁互斥量
done_path_create(&parent, dentry);
return 0;
vfs_mknod()
vfs_mknod()是内核中的一个函数,用于在文件系统中创建设备节点或普通文件。
int vfs_mknod(struct mnt_idmap *idmap, struct inode *dir,
struct dentry *dentry, umode_t mode, dev_t dev)
{
// is_whiteout:检查创建的节点是否为“whiteout”设备节点(特定场景下表示覆盖的字符设备节点)。这是一个特殊类型,用于某些文件系统操作,比如在 overlay 文件系统中。
bool is_whiteout = S_ISCHR(mode) && dev == WHITEOUT_DEV;
// may_create():检查是否有权限在父目录中创建新文件或设备节点。如果没有权限,则直接返回错误。
int error = may_create(idmap, dir, dentry);
if (error)
return error;
//S_ISCHR(mode) 和 S_ISBLK(mode):判断所要创建的节点是否为字符设备或块设备。如果是字符设备或块设备节点,且不是 "whiteout",则需要调用 capable(CAP_MKNOD) 来检查是否具有创建设备节点的权限(通常是超级用户权限)。如果没有权限,返回 -EPERM(操作不允许)。
if ((S_ISCHR(mode) || S_ISBLK(mode)) && !is_whiteout &&
!capable(CAP_MKNOD))
return -EPERM;
// 检查父目录的 inode 操作 (i_op) 是否支持 mknod,即是否具有创建设备节点的功能。如果父目录不支持该操作,则返回 -EPERM。
if (!dir->i_op->mknod)
return -EPERM;
mode = vfs_prepare_mode(idmap, dir, mode, mode, mode);
error = devcgroup_inode_mknod(mode, dev);
if (error)
return error;
error = security_inode_mknod(dir, dentry, mode, dev);
if (error)
return error;
// dir->i_op->mknod():实际调用文件系统提供的 mknod 操作来创建设备节点。这个操作由具体的文件系统实现(如 EXT4、XFS 等)。
error = dir->i_op->mknod(idmap, dir, dentry, mode, dev);
if (!error)
fsnotify_create(dir, dentry);
return error;
}
EXPORT_SYMBOL(vfs_mknod);
问题:所以sock文件到底是socket函数创建的还是bind函数创建的?
答:
sock文件(即 UNIX domain socket 文件)实际上是在bind()函数的执行过程中创建的,而不是在调用socket()函数时创建的。
socket()函数的作用
socket()函数创建的是套接字的内核对象,返回一个文件描述符(fd),用于表示一个套接字。- 当你调用
socket()函数时,内核会为该套接字分配必要的内核结构体(例如struct socket和struct sock),并初始化与该套接字相关的内核数据结构。- 在这一步,虽然套接字的对象已经存在,但还没有与具体的文件系统路径进行关联。因此,这时候并没有产生任何文件系统中的节点(
sock文件)。
bind()函数的作用
bind()函数的作用是将套接字与一个具体的地址绑定。在 UNIX domain socket 的场景下,这个地址可以是一个文件系统中的路径,也可以是一个抽象名称。- 对于 BSD 风格 的 UNIX domain socket,调用
bind()函数时,会在文件系统中创建一个文件节点,这个节点就是我们在文件系统中看到的.sock文件,或者是类似/tmp/mysocket的文件。- 具体来说,
bind()函数中会调用vfs_mknod(),它在文件系统中创建一个新的文件节点(类型为S_IFSOCK),并把这个节点与套接字相关联。这样,其他进程就可以通过该路径找到这个套接字,从而进行通信。
sock文件的创建过程以下是
sock文件创建的关键步骤:(1)调用
socket()函数:
创建套接字对象,并返回一个文件描述符,标识这个套接字。
此时,内核中创建了套接字的相关数据结构,但文件系统中并没有任何体现。
(2)调用
bind()函数:
- 将套接字与具体的地址绑定。对于 UNIX domain socket,这个地址是一个文件系统路径(BSD 风格)或抽象路径。
- 如果是 BSD 风格的地址,
bind()函数会在文件系统中为该地址创建一个文件节点。比如/tmp/mysocket。- 内核中会调用
vfs_mknod()或类似的文件系统函数来创建设备节点,确保在文件系统中有一个对应的文件,表示该 UNIX domain socket 地址。- 如果是抽象地址,则没有文件系统节点的创建,仅在内核中维护相应的抽象路径。
listen()
一句话概括listen函数:将套接字状态设置为监听模式。
//syscall
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
return __sys_listen(fd, backlog);
}
listen()->sys_listen()
这段代码实现了内核中
listen()系统调用的核心部分。它用于将一个套接字转换为被动连接模式,开始监听来自客户端的连接请求。
int __sys_listen(int fd, int backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
//sockfd_lookup_light() 用于查找与给定文件描述符 fd 关联的套接字对象 (struct socket)。
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
//设置最大连接数 (somaxconn)
somaxconn = READ_ONCE(sock_net(sock->sk)->core.sysctl_somaxconn);
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
// 调用协议栈的 listen() 函数,将套接字转换为监听模式。
err = READ_ONCE(sock->ops)->listen(sock, backlog);
// 释放文件引用:
fput_light(sock->file, fput_needed);
}
return err;
}
sys_listen()->unix_listen()
static int unix_listen(struct socket *sock, int backlog)
{
int err; // 错误码
struct sock *sk = sock->sk; // 获取套接字的基础结构
struct unix_sock *u = unix_sk(sk); // 获取UNIX套接字结构
err = -EOPNOTSUPP;
// 检查套接字类型是否为 SOCK_STREAM 或 SOCK_SEQPACKET
if (sock->type != SOCK_STREAM && sock->type != SOCK_SEQPACKET) // 仅有流套接字和顺序包套接字支持监听
goto out;
err = -EINVAL;
// 检查是否绑定地址,未绑定地址的套接字不能进行监听
if (!u->addr)
goto out;
unix_state_lock(sk); // 锁定套接字状态
// 检查套接字状态是否为 TCP_CLOSE 或 TCP_LISTEN
if (sk->sk_state != TCP_CLOSE && sk->sk_state != TCP_LISTEN)
goto out_unlock; // 套接字状态必须为关闭或监听
// 如果新的SYN等待队列大小大于当前的SYN最大等待队列大小,则唤醒所有SYN等待队列中的对等体
if (backlog > sk->sk_max_ack_backlog)
wake_up_interruptible_all(&u->peer_wait);
sk->sk_max_ack_backlog = backlog; // 设置新的等待队列大小
sk->sk_state = TCP_LISTEN; // 将套接字状态设置为监听
// 设置连接的凭证,以便连接操作可以复制它们
init_peercred(sk);
err = 0;
out_unlock:
unix_state_unlock(sk); // 解锁套接字状态
out:
return err; // 返回错误码
}
connect()
一句话概括connect函数:实现了 UNIX domain socket 的连接逻辑。它处理了客户端套接字连接到服务器监听套接字的过程。
//syscall
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uwservaddr,
int, addrlen)
{
return __sys_connect(fd, uservaddr, addrlen);
}
connect()->__sys_connect()
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
int ret = -EBADF;
struct fd f;
// 获取文件描述符的X文件对象 (fdget()):
f = fdget(fd);
if (f.file) {
struct sockaddr_storage address;
// move_addr_to_kernel():将用户空间的地址(uservaddr)移动到内核空间的 address 结构中。这一步将用户提供的地址拷贝到内核中,以便内核能够安全地使用它。
ret = move_addr_to_kernel(uservaddr, addrlen, &address);
if (!ret)
// __sys_connect_file():这是一个实际进行连接操作的函数。它接收文件对象(即套接字)、内核中的地址结构以及地址长度,完成连接操作。
ret = __sys_connect_file(f.file, &address, addrlen, 0);
fdput(f);
}
return ret;
}
__sys_connect()->__sys_connect_file()
int __sys_connect_file(struct file *file, struct sockaddr_storage *address,
int addrlen, int file_flags)
{
struct socket *sock;
int err;
// 获取套接字对象
sock = sock_from_file(file);
if (!sock) {
err = -ENOTSOCK;
goto out;
}
// security_socket_connect():调用 Linux 安全模块(LSM)进行安全检查,确保当前用户或进程有权限对指定的套接字发起连接请求。
err =
security_socket_connect(sock, (struct sockaddr *)address, addrlen);
if (err)
goto out;
// READ_ONCE(sock->ops):读取套接字操作表。由于套接字的操作表可能会被多线程并发修改,使用 READ_ONCE() 确保读取的值是最新的。
// sock->ops->connect():调用套接字的 connect 操作函数,执行实际的连接操作。
err = READ_ONCE(sock->ops)->connect(sock, (struct sockaddr *)address,
addrlen, sock->file->f_flags | file_flags);
out:
return err;
}
**注意:**这里
(sock->ops)->connect()会根据套接字的类型调用不同的实现函数,例如SOCK_STREAM会调用unix_stream_connect(),SOCK_DGRAM:会调用unix_dgram_connect()。在 UNIX domain socket 中,套接字的类型取决于在调用
socket()函数时所指定的类型参数。主要有以下几种类型:
- SOCK_STREAM (流式套接字):
- 在你提供的代码中,使用了
SOCK_STREAM,这意味着套接字是流式的,类似于 TCP 协议的套接字。- 特性:面向连接,提供可靠的、按顺序的、无数据丢失的通信,适用于需要可靠传输的场景。
- 我的
server.c和client.c文件中都使用了AF_UNIX和SOCK_STREAM,因此这两个套接字是可靠的面向连接的流式套接字。- SOCK_DGRAM (数据报套接字):
- 这是另一种类型的 UNIX domain socket,类似于 UDP 协议的套接字。
- 特性:面向无连接,传输不保证顺序或可靠性,适用于对可靠性要求较低但速度较快的场景。
- 使用
SOCK_DGRAM可以在 UNIX domain 中实现无连接的数据报通信。- SOCK_SEQPACKET (有序分组套接字):
- 这是 UNIX domain socket 中的一种较少使用的类型。
- 特性:面向连接,提供可靠的、有序的数据传输,但不像
SOCK_STREAM那样是一个连续的数据流,而是一个有序的数据包序列。- 适用于需要有序传输数据包的应用。
unix_stream_connect()函数实现了 UNIX domain socket 的连接逻辑。它处理了客户端套接字连接到服务器监听套接字的过程。
static int unix_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
// 将传入的通用地址结构转换为 UNIX 专用地址结构
struct sockaddr_un *sunaddr = (struct sockaddr_un *)uaddr;
struct sock *sk = sock->sk, *newsk = NULL, *other = NULL;
struct unix_sock *u = unix_sk(sk), *newu, *otheru;
struct net *net = sock_net(sk);
struct sk_buff *skb = NULL;
long timeo;X@
int err;
int st;
// 验证传入的地址是否有效
err = unix_validate_addr(sunaddr, addr_len);
if (err)
goto out;
// 如果套接字需要传递凭据但尚未绑定,则进行自动绑定
if ((test_bit(SOCK_PASSCRED, &sock->flags) ||
test_bit(SOCK_PASSPIDFD, &sock->flags)) && !u->addr) {
err = unix_autobind(sk);
if (err)
goto out;
}
// 设置超时时间,取决于是否为非阻塞模式
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
// 创建一个新的套接字,用于代表即将建立的连接
newsk = unix_create1(net, NULL, 0, sock->type);
if (IS_ERR(newsk)) {
err = PTR_ERR(newsk);
newsk = NULL;
goto out;
}
err = -ENOMEM;
// 为新的套接字分配sk_buff
skb = sock_wmalloc(newsk, 1, 0, GFP_KERNEL);
if (skb == NULL)
goto out;
restart:
// 查找监听套接字
other = unix_find_other(net, sunaddr, addr_len, sk->sk_type);
if (IS_ERR(other)) {
err = PTR_ERR(other);
other = NULL;
goto out;
}
// 锁定目标套接字的状态
unix_state_lock(other);
// 如果目标套接字已死亡,解锁并重新查找
if (sock_flag(other, SOCK_DEAD)) {
unix_state_unlock(other);
sock_put(other);
goto restart;
}
// 检查目标套接字是否在监听状态,或已关闭接收
err = -ECONNREFUSED;
if (other->sk_state != TCP_LISTEN)
goto out_unlock;
if (other->sk_shutdown & RCV_SHUTDOWN)
goto out_unlock;
// 如果目标监听套接字的接收队列已满,则等待直到有空间或超时
if (unix_recvq_full(other)) {
err = -EAGAIN;
if (!timeo)
goto out_unlock;
timeo = unix_wait_for_peer(other, timeo);
err = sock_intr_errno(timeo);
if (signal_pending(current))
goto out;
sock_put(other);
goto restart;
}
// 锁定发起连接的套接字状态
st = sk->sk_state;
switch (st) {
case TCP_CLOSE:
// 套接字处于关闭状态,可以继续连接
break;
case TCP_ESTABLISHED:
// 套接字已经连接
err = -EISCONN;
goto out_unlock;
default:
err = -EINVAL;
goto out_unlock;
}
unix_state_lock_nested(sk);
// 在锁定状态下重新检查套接字状态,确保没有变化
if (sk->sk_state != st) {
unix_state_unlock(sk);
unix_state_unlock(other);
sock_put(other);
goto restart;
}
// 进行安全性检查
err = security_unix_stream_connect(sk, other, newsk);
if (err) {
unix_state_unlock(sk);
goto out_unlock;
}
// 设置新套接字以完成连接
sock_hold(sk);
unix_peer(newsk) = sk;
newsk->sk_state = TCP_ESTABLISHED;
newsk->sk_type = sk->sk_type;
init_peercred(newsk);
newu = unix_sk(newsk);
RCU_INIT_POINTER(newsk->sk_wq, &newu->peer_wq);
otheru = unix_sk(other);
// 从监听套接字复制地址信息到新套接字
if (otheru->path.dentry) {
path_get(&otheru->path);
newu->path = otheru->path;
}
refcount_inc(&otheru->addr->refcnt);
smp_store_release(&newu->addr, otheru->addr);
// 设置新套接字的凭据
copy_peercred(sk, other);
// 更新客户端套接字和新套接字的状态为已连接
sock->state = SS_CONNECTED;
sk->sk_state = TCP_ESTABLISHED;
sock_hold(newsk);
smp_mb__after_atomic();
unix_peer(sk) = newsk;
unix_state_unlock(sk);
// 将连接信息发送给监听套接字
spin_lock(&other->sk_receive_queue.lock);
__skb_queue_tail(&other->sk_receive_queue, skb);
spin_unlock(&other->sk_receive_queue.lock);
unix_state_unlock(other);
other->sk_data_ready(other);
sock_put(other);
return 0;
out_unlock:
if (other)
unix_state_unlock(other);
out:
kfree_skb(skb);
if (newsk)
unix_release_sock(newsk, 0);
if (other)
sock_put(other);
return err;
}
unix_find_other():查找对方正在监听的套接字
static struct sock *unix_find_other(struct net *net,
struct sockaddr_un *sunaddr,
int addr_len, int type)
{
struct sock *sk;
if (sunaddr->sun_path[0])
sk = unix_find_bsd(sunaddr, addr_len, type);
else
sk = unix_find_abstract(net, sunaddr, addr_len, type);
return sk;
}
这里有两个查找函数,我们选择bsd风格分析。
unix_find_bsd()函数用于在文件系统中查找与 BSD 风格地址绑定的 UNIX domain socket。它通过给定的路径名找到对应的文件(套接字),并返回与之关联的sock结构体。以下是对该函数的逐步分析和中文注释。
static struct sock *unix_find_bsd(struct sockaddr_un *sunaddr, int addr_len,
int type)
{
struct inode *inode;
struct path path;
struct sock *sk;
int err;
// 构建 BSD 风格地址,确保 sun_path 合法
unix_mkname_bsd(sunaddr, addr_len);
// 使用 kern_path 查找给定路径对应的文件对象
err = kern_path(sunaddr->sun_path, LOOKUP_FOLLOW, &path);
if (err)
goto fail;
// 检查对路径的写权限,以确保能够绑定
err = path_permission(&path, MAY_WRITE);
if (err)
goto path_put;
// 检查该路径对应的 inode 是否为套接字类型
err = -ECONNREFUSED;
inode = d_backing_inode(path.dentry);
if (!S_ISSOCK(inode->i_mode))
goto path_put;
// 查找 inode 对应的套接字对象
sk = unix_find_socket_byinode(inode);
if (!sk)
goto path_put;
// 确保套接字类型一致
err = -EPROTOTYPE;
if (sk->sk_type == type)
touch_atime(&path); // 更新访问时间
else
goto sock_put;
// 释放路径资源
path_put(&path);
return sk;
sock_put:
// 释放套接字引用
sock_put(sk);
path_put:
// 释放路径引用
path_put(&path);
fail:
// 返回错误指针
return ERR_PTR(err);
}
accept()
从监听套接字中接受一个新连接,并将新连接的套接字信息复制到传入的一个新的套接字
// syscall
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
{
return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
}
accept()->__sys_accept4()
int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags)
{
int ret = -EBADF;
struct fd f;
f = fdget(fd);
if (f.file) {
ret = __sys_accept4_file(f.file, upeer_sockaddr,
upeer_addrlen, flags);
fdput(f);
}
return ret;
}
__sys_accept4()->__sys_accept4_file()
__sys_accept4_file()函数实现了对已存在套接字文件的accept操作,该函数用于从文件描述符中获取新连接。它允许对新的套接字设置一些标志,比如非阻塞和关闭文件描述符时自动执行close。
static int __sys_accept4_file(struct file *file, struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags)
{
struct file *newfile;
int newfd;
// 检查 flags,确保它们是合法的,不能有除 SOCK_CLOEXEC 和 SOCK_NONBLOCK 之外的其他标志
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
// 如果 SOCK_NONBLOCK 与 O_NONBLOCK 不相等且设置了 SOCK_NONBLOCK,则转换为 O_NONBLOCK
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
// 获取一个新的文件描述符
newfd = get_unused_fd_flags(flags);
if (unlikely(newfd < 0))
return newfd;
// 使用 do_accept 函数接受连接,返回新的文件对象
newfile = do_accept(file, 0, upeer_sockaddr, upeer_addrlen, flags);
if (IS_ERR(newfile)) {
// 如果出错,则释放之前获取的文件描述符
put_unused_fd(newfd);
return PTR_ERR(newfile);
}
// 将新的文件对象安装到新获取的文件描述符上
fd_install(newfd, newfile);
return newfd;
}
__sys_accept4_file()->do_accept()
do_accept()函数用于接受传入的连接请求,为新的连接创建套接字,并返回一个与新连接关联的文件对象。该函数是处理accept系统调用的核心部分,主要负责资源的分配和连接的建立。
struct file *do_accept(struct file *file, unsigned file_flags,
struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len;
struct sockaddr_storage address;
const struct proto_ops *ops;
// 从文件对象获取套接字
sock = sock_from_file(file);
if (!sock)
return ERR_PTR(-ENOTSOCK);
// 为新的连接分配套接字
newsock = sock_alloc();
if (!newsock)
return ERR_PTR(-ENFILE);
// 获取原始套接字的操作指针
ops = READ_ONCE(sock->ops);
// 设置新套接字的类型和操作指针
newsock->type = sock->type;
newsock->ops = ops;
/*
* 我们不需要调用 try_module_get,因为监听套接字 (sock) 已经持有了
* 协议模块 (sock->ops->owner)。
*/
__module_get(ops->owner);
// 为新套接字分配文件对象,并使用给定的标志
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
if (IS_ERR(newfile))
return newfile;
// 进行安全检查,确保可以接受连接
err = security_socket_accept(sock, newsock);
if (err)
goto out_fd;
// 调用套接字的 accept 操作以建立新连接
err = ops->accept(sock, newsock, sock->file->f_flags | file_flags, false);
if (err < 0)
goto out_fd;
// 如果需要,获取对等端的地址信息
if (upeer_sockaddr) {
len = ops->getname(newsock, (struct sockaddr *)&address, 2);
if (len < 0) {
err = -ECONNABORTED;
goto out_fd;
}
err = move_addr_to_user(&address, len, upeer_sockaddr, upeer_addrlen);
if (err < 0)
goto out_fd;
}
/* 文件标志不会通过 accept() 继承,这与其他操作系统不同。 */
return newfile;
out_fd:
// 释放新文件对象的引用,释放资源
fput(newfile);
return ERR_PTR(err);
}
do_accept()->unix_accept()
unix_accept()函数用于实现 UNIX domain socket 的accept操作,它从监听套接字中接受一个新连接,并将新连接的套接字信息复制到传入的newsock中。
static int unix_accept(struct socket *sock, struct socket *newsock, int flags, bool kern)
{
struct sock *sk = sock->sk;
struct sock *tsk;
struct sk_buff *skb;
int err;
// 如果套接字类型不是 SOCK_STREAM 或 SOCK_SEQPACKET,则返回不支持的错误
err = -EOPNOTSUPP;
if (sock->type != SOCK_STREAM && sock->type != SOCK_SEQPACKET)
goto out;
// 如果套接字状态不是 TCP_LISTEN,则返回无效参数错误
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
goto out;
/* 如果套接字状态为 TCP_LISTEN,它在此处不会改变(暂时...),因此不需要加锁。 */
// 尝试从监听套接字的接收队列中获取数据包
skb = skb_recv_datagram(sk, (flags & O_NONBLOCK) ? MSG_DONTWAIT : 0, &err);
if (!skb) {
// 如果接收队列为空并且发生接收关闭,返回错误
if (err == 0)
err = -EINVAL;
goto out;
}
// 获取新连接的套接字
tsk = skb->sk;
skb_free_datagram(sk, skb);
// 唤醒等待连接的进程
wake_up_interruptible(&unix_sk(sk)->peer_wait);
// 将新连接的套接字附加到传入的 newsock 上
unix_state_lock(tsk);
newsock->state = SS_CONNECTED;
unix_sock_inherit_flags(sock, newsock);
sock_graft(tsk, newsock);
unix_state_unlock(tsk);
return 0;
out:
return err;
}
write()
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
return ksys_write(fd, buf, count);
}
write()->ksys_write()
ksys_write()是 Linux 内核中实现的一个系统调用处理函数,用于处理来自用户态的write()系统调用。在这个函数中,它接收了一个文件描述符fd、一个用户空间的缓冲区buf以及写入的字节数count,并通过相应的文件系统接口将数据写入目标文件或设备。
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
// 确保文件描述符有效
if (f.file) {
// file_ppos(f.file):该函数用于获取文件的当前偏移量指针。对于某些文件类型(如常规文件),偏移量需要不断更新,而对于某些特殊文件(如 socket),可能不需要偏移量。
loff_t pos, *ppos = file_ppos(f.file);
// 如果文件指针存在,设置写入的起始位置
if (ppos) {
pos = *ppos;
ppos = &pos;
}
// 调用 vfs_write 进行实际的写入操作,具体的写入操作将由不同的文件系统或设备驱动来实现,例如字符设备、块设备、网络套接字等。
ret = vfs_write(f.file, buf, count, ppos);
// 更新文件的偏移量
if (ret >= 0 && ppos)
f.file->f_pos = pos;
// 释放文件描述符引用
fdput_pos(f);
}
return ret;
}
ksys_write()->vfs_write()
vfs_write()是 Linux 内核中用于处理文件写入操作的虚拟文件系统(VFS)接口函数。它接收一个struct file指针、用户空间缓冲区、要写入的字节数以及文件的偏移量指针,负责执行实际的数据写入操作。
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
// 检查文件是否具有写权限
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
// 检查文件是否可以写
if (!(file->f_mode & FMODE_CAN_WRITE))
return -EINVAL;
// 检查用户空间缓冲区是否可访问
if (unlikely(!access_ok(buf, count)))
return -EFAULT;
// 验证写入区域是否合法
ret = rw_verify_area(WRITE, file, pos, count);
if (ret)
return ret;
// 限制写入字节数,避免过大的写入
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
// file_start_write():用于文件系统的并发控制,开始写操作。某些文件系统需要这种机制来确保数据一致性。
file_start_write(file);
// 调用具体的写入函数
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos); // 旧版写入接口
else if (file->f_op->write_iter)
ret = new_sync_write(file, buf, count, pos); // 新版写入接口
else
ret = -EINVAL;
// 如果写入成功,进行通知和更新统计
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
// 更新写入系统调用计数
inc_syscw(current);
// 结束写操作
file_end_write(file);
return ret;
}
vfs_write()->sock_write_iter()
sock_write_iter()是用于实现套接字文件写入的函数,支持通过迭代接口 (write_iter)来完成写入操作。该函数从用户空间获取数据并写入到与之关联的套接字中。
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {.msg_iter = *from,
.msg_iocb = iocb};
ssize_t res;
// 如果文件偏移量不为0,则返回-ESPIPE错误,因为套接字是流式文件,不支持位置调整
if (iocb->ki_pos != 0)
return -ESPIPE;
// 如果文件是非阻塞模式或者IOCB标志设置了不等待,则设置消息标志MSG_DONTWAIT
if (file->f_flags & O_NONBLOCK || (iocb->ki_flags & IOCB_NOWAIT))
msg.msg_flags = MSG_DONTWAIT;
// 如果套接字类型是顺序包(SOCK_SEQPACKET),设置消息标志MSG_EOR
if (sock->type == SOCK_SEQPACKET)
msg.msg_flags |= MSG_EOR;
// 调用内核函数发送消息
res = __sock_sendmsg(sock, &msg);
// 更新迭代器状态
*from = msg.msg_iter;
return res;
}
__sock_sendmsg()->__sock_sendmsg()
static int __sock_sendmsg(struct socket *sock, struct msghdr *msg)
{
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
__sock_sendmsg()->sock_sendmsg_nosec()
sock_sendmsg_nosec()是一个内核中的静态内联函数,主要用于发送消息(sendmsg)的操作。这个函数的作用是将用户空间的消息封装后,通过调用套接字协议的发送函数,将数据发送到相应的网络栈中。
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
// READ_ONCE(sock->ops)->sendmsg:使用 READ_ONCE 读取套接字的操作结构体(sock->ops)中的 sendmsg 函数指针,确保读取的原子性。sendmsg 是不同协议的实现函数,这里通过动态判断协议类型并调用合适的 sendmsg 函数,先调用sock->ops->sendmsg,若为空,则会调用IPv4 或 IPv6 。
int ret = INDIRECT_CALL_INET(READ_ONCE(sock->ops)->sendmsg, inet6_sendmsg,
inet_sendmsg, sock, msg,
msg_data_left(msg));
BUG_ON(ret == -EIOCBQUEUED);
if (trace_sock_send_length_enabled())
call_trace_sock_send_length(sock->sk, ret, 0);
return ret;
}
sock_sendmsg_nosec()->unix_stream_sendmsg()
unix_stream_sendmsg()是用于 Unix 域套接字的数据发送函数,支持流式 (SOCK_STREAM) 套接字。它负责将用户空间的数据通过套接字发送给已连接的另一端。
static int unix_stream_sendmsg(struct socket *sock, struct msghdr *msg, size_t len)
{
struct sock *sk = sock->sk;
struct sock *other = NULL;
int err, size;
struct sk_buff *skb;
int sent = 0;
struct scm_cookie scm;
bool fds_sent = false;
int data_len;
// 等待 Unix 垃圾回收完成
wait_for_unix_gc();
// 处理控制信息
err = scm_send(sock, msg, &scm, false);
if (err < 0)
return err;
// 不支持 MSG_OOB(带外数据)
err = -EOPNOTSUPP;
if (msg->msg_flags & MSG_OOB) {
#if IS_ENABLED(CONFIG_AF_UNIX_OOB)
if (len)
len--;
else
#endif
goto out_err;
}
// 验证是否有目标连接
if (msg->msg_namelen) {
err = sk->sk_state == TCP_ESTABLISHED ? -EISCONN : -EOPNOTSUPP;
goto out_err;
} else {
err = -ENOTCONN;
other = unix_peer(sk);
if (!other)
goto out_err;
}
// 检查发送端是否已经关闭
if (sk->sk_shutdown & SEND_SHUTDOWN)
goto pipe_err;
// 循环发送数据
while (sent < len) {
size = len - sent;
if (unlikely(msg->msg_flags & MSG_SPLICE_PAGES)) {
// 使用 splice 方法分配发送缓冲区
skb = sock_alloc_send_pskb(sk, 0, 0,
msg->msg_flags & MSG_DONTWAIT,
&err, 0);
} else {
// 以发送缓冲区的一半大小为最大值,避免阻塞
size = min_t(int, size, (sk->sk_sndbuf >> 1) - 64);
// 限制 size 以保证可以进行 order-0 分配
size = min_t(int, size, SKB_MAX_HEAD(0) + UNIX_SKB_FRAGS_SZ);
data_len = max_t(int, 0, size - SKB_MAX_HEAD(0));
data_len = min_t(size_t, size, PAGE_ALIGN(data_len));
// 分配发送缓冲区
skb = sock_alloc_send_pskb(sk, size - data_len, data_len,
msg->msg_flags & MSG_DONTWAIT, &err,
get_order(UNIX_SKB_FRAGS_SZ));
}
if (!skb)
goto out_err;
// 将文件描述符仅在第一个缓冲区中发送
err = unix_scm_to_skb(&scm, skb, !fds_sent);
if (err < 0) {
kfree_skb(skb);
goto out_err;
}
fds_sent = true;
// 使用 splice 进行数据拷贝
if (unlikely(msg->msg_flags & MSG_SPLICE_PAGES)) {
err = skb_splice_from_iter(skb, &msg->msg_iter, size, sk->sk_allocation);
if (err < 0) {
kfree_skb(skb);
goto out_err;
}
size = err;
refcount_add(size, &sk->sk_wmem_alloc);
} else {
skb_put(skb, size - data_len);
skb->data_len = data_len;
skb->len = size;
// 将数据从迭代器拷贝到发送缓冲区
err = skb_copy_datagram_from_iter(skb, 0, &msg->msg_iter, size);
if (err) {
kfree_skb(skb);
goto out_err;
}
}
// 锁住对端套接字
unix_state_lock(other);
// 如果对端套接字已关闭,跳转到错误处理
if (sock_flag(other, SOCK_DEAD) || (other->sk_shutdown & RCV_SHUTDOWN))
goto pipe_err_free;
// 添加凭据
maybe_add_creds(skb, sock, other);
scm_stat_add(other, skb);
// 将数据包加入到对端的接收队列
skb_queue_tail(&other->sk_receive_queue, skb);
unix_state_unlock(other);
// 通知对端有新数据
other->sk_data_ready(other);
sent += size;
}
#if IS_ENABLED(CONFIG_AF_UNIX_OOB)
// 处理带外数据
if (msg->msg_flags & MSG_OOB) {
err = queue_oob(sock, msg, other, &scm, fds_sent);
if (err)
goto out_err;
sent++;
}
#endif
// 销毁控制信息
scm_destroy(&scm);
return sent;
pipe_err_free:
unix_state_unlock(other);
kfree_skb(skb);
pipe_err:
// 如果发送失败,且非 MSG_NOSIGNAL,则发送 SIGPIPE 信号
if (sent == 0 && !(msg->msg_flags & MSG_NOSIGNAL))
send_sig(SIGPIPE, current, 0);
err = -EPIPE;
out_err:
scm_destroy(&scm);
return sent ? : err;
}
unix_stream_sendmsg函数中将将数据从迭代器拷贝到skb中有两种不同的方法:使用splice方法(skb_splice_from_iter)和普通方法(skb_copy_datagram_from_iter)
注:splice方法会在启用MSG_SPLICE_PAGES选项时使用。
这里我们介绍普通方法 skb_copy_datagram_from_iter()
skb_copy_datagram_from_iter()是 Linux 内核中用于将数据从iov_iter迭代器复制到套接字缓冲区 (sk_buff) 中的函数。它用于处理数据的拷贝过程,将用户空间或内核中的数据传递到sk_buff,以便进行进一步的网络传输或处理。
int skb_copy_datagram_from_iter(struct sk_buff *skb, int offset,
struct iov_iter *from,
int len)
{
int start = skb_headlen(skb);
int i, copy = start - offset;
struct sk_buff *frag_iter;
/* Copy header. */
// 首先将头部数据复制到缓冲区中
if (copy > 0) {
if (copy > len)
copy = len;
if (copy_from_iter(skb->data + offset, copy, from) != copy)
goto fault;
if ((len -= copy) == 0)
return 0;
offset += copy;
}
/* Copy paged appendix. Hmm... why does this look so complicated? */
// 处理页片段的数据拷贝
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
size_t copied;
if (copy > len)
copy = len;
copied = copy_page_from_iter(skb_frag_page(frag),
skb_frag_off(frag) + offset - start,
copy, from);
if (copied != copy)
goto fault;
if (!(len -= copy))
return 0;
offset += copy;
}
start = end;
}
/* Copy data from skb fragments (e.g., GSO fragments) */
skb_walk_frags(skb, frag_iter) {
int end;
WARN_ON(start > offset + len);
end = start + frag_iter->len;
if ((copy = end - offset) > 0) {
if (copy > len)
copy = len;
if (skb_copy_datagram_from_iter(frag_iter,
offset - start,
from, copy))
goto fault;
if ((len -= copy) == 0)
return 0;
offset += copy;
}
start = end;
}
if (!len)
return 0;
fault:
return -EFAULT;
}
read()
// syscall
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}
read()->ksys_read()
ksys_read函数是 Linux 内核中用于读取文件描述符内容的函数。它的目的是从指定的文件描述符 (fd) 中读取数据到用户提供的缓冲区 (buf) 中,并返回读取的字节数。
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos, *ppos = file_ppos(f.file);
if (ppos) {
pos = *ppos;
ppos = &pos;
}
// 调用 vfs_read() 函数执行实际的文件读取操作
ret = vfs_read(f.file, buf, count, ppos);
if (ret >= 0 && ppos)
f.file->f_pos = pos;
fdput_pos(f);
}
return ret;
}
ksys_read()->vfs_read()
vfs_read函数负责从文件对象读取数据并将其拷贝到用户空间的缓冲区中。
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
// 检查文件是否可读
if (!(file->f_mode & FMODE_READ))
return -EBADF;
// 检查文件是否允许读取操作
if (!(file->f_mode & FMODE_CAN_READ))
return -EINVAL;
// 检查用户空间缓冲区的有效性
if (unlikely(!access_ok(buf, count)))
return -EFAULT;
// 调用 rw_verify_area() 验证读取的区域是否合法,主要用于检查文件的偏移量和读取的字节数是否超出了文件边界。
ret = rw_verify_area(READ, file, pos, count);
if (ret)
return ret;
// 限制读取字节数
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
// 执行读取操作,这里会调用sock_read_iter
if (file->f_op->read) //旧
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter) //新
ret = new_sync_read(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
// 更新读取的统计信息
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
return ret;
}
vfs_read()->sock_read_iter()
sock_read_iter()是 Linux 内核中用于处理套接字读取操作的函数。它用于从套接字中读取数据,并将数据写入用户空间的缓冲区中。这个函数利用kiocb和iov_iter结构来支持异步和向量化的 I/O 操作。
static ssize_t sock_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {.msg_iter = *to,
.msg_iocb = iocb};
ssize_t res;
// 如果文件标志包含 O_NONBLOCK 或 iocb 中的标志包含 IOCB_NOWAIT,则设置非阻塞标志
if (file->f_flags & O_NONBLOCK || (iocb->ki_flags & IOCB_NOWAIT))
msg.msg_flags = MSG_DONTWAIT;
// 确保偏移量为 0,因为 socket 不能进行偏移读写
if (iocb->ki_pos != 0)
return -ESPIPE;
// 如果迭代器没有数据需要写入,直接返回 0
if (!iov_iter_count(to)) /* Match SYS5 behaviour */
return 0;
// 调用 sock_recvmsg 来接收消息
res = sock_recvmsg(sock, &msg, msg.msg_flags);
// 更新迭代器的状态
*to = msg.msg_iter;
return res;
}
sock_read_iter()->sock_recvmsg()
int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags)
{
int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags);
return err ?: sock_recvmsg_nosec(sock, msg, flags);
}
sock_recvmsg()->sock_recvmsg_nosec()
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg,
int flags)
{
int ret = INDIRECT_CALL_INET(READ_ONCE(sock->ops)->recvmsg,
inet6_recvmsg,
inet_recvmsg, sock, msg,
msg_data_left(msg), flags);
if (trace_sock_recv_length_enabled())
call_trace_sock_recv_length(sock->sk, ret, flags);
return ret;
}
sock_recvmsg_nosec()->unix_stream_recvmsg()
unix_stream_recvmsg()是 Linux 内核中处理 UNIX 域套接字流类型的消息接收函数。它主要用于从流式 UNIX 域套接字中接收数据并填充到msghdr结构中。
static int unix_stream_recvmsg(struct socket *sock, struct msghdr *msg,
size_t size, int flags)
{
struct unix_stream_read_state state = {
.recv_actor = unix_stream_read_actor,
.socket = sock,
.msg = msg,
.size = size,
.flags = flags
};
#ifdef CONFIG_BPF_SYSCALL
struct sock *sk = sock->sk;
const struct proto *prot = READ_ONCE(sk->sk_prot);
// 如果套接字协议不是 UNIX 域协议,则调用其他协议的 recvmsg 方法
if (prot != &unix_stream_proto)
return prot->recvmsg(sk, msg, size, flags, NULL);
#endif
// 调用通用的 UNIX 流读取函数
return unix_stream_read_generic(&state, true);
}
unix_stream_recvmsg()->unix_stream_read_generic()
unix_stream_read_generic()是一个用于从 UNIX 域套接字流中读取数据的函数。它管理从内核中的套接字缓冲区 (sk_buff) 中读取数据的整个过程,并处理多个复杂场景,包括非阻塞读取、接收外带数据(OOB)、等待数据可用等。
static int unix_stream_read_generic(struct unix_stream_read_state *state,
bool freezable)
{
struct scm_cookie scm;
struct socket *sock = state->socket;
struct sock *sk = sock->sk;
struct unix_sock *u = unix_sk(sk);
int copied = 0;
int flags = state->flags;
int noblock = flags & MSG_DONTWAIT;
bool check_creds = false;
int target;
int err = 0;
long timeo;
int skip;
size_t size = state->size;
unsigned int last_len;
if (unlikely(sk->sk_state != TCP_ESTABLISHED)) {
err = -EINVAL;
goto out;
}
if (unlikely(flags & MSG_OOB)) {
err = -EOPNOTSUPP;
#if IS_ENABLED(CONFIG_AF_UNIX_OOB)
err = unix_stream_recv_urg(state);
#endif
goto out;
}
// 获取 socket 读取的低水位标记
target = sock_rcvlowat(sk, flags & MSG_WAITALL, size);
timeo = sock_rcvtimeo(sk, noblock);
memset(&scm, 0, sizeof(scm));
// 加锁以防止在读取过程中发生队列混乱
mutex_lock(&u->iolock);
skip = max(sk_peek_offset(sk, flags), 0);
do {
int chunk;
bool drop_skb;
struct sk_buff *skb, *last;
redo:
// 锁定套接字的状态以进行安全的数据读取
unix_state_lock(sk);
if (sock_flag(sk, SOCK_DEAD)) {
err = -ECONNRESET;
goto unlock;
}
last = skb = skb_peek(&sk->sk_receive_queue);
last_len = last ? last->len : 0;
#if IS_ENABLED(CONFIG_AF_UNIX_OOB)
if (skb) {
skb = manage_oob(skb, sk, flags, copied);
if (!skb) {
unix_state_unlock(sk);
if (copied)
break;
goto redo;
}
}
#endif
again:
if (skb == NULL) {
if (copied >= target)
goto unlock;
// 检查 socket 错误
err = sock_error(sk);
if (err)
goto unlock;
// 检查接收端关闭
if (sk->sk_shutdown & RCV_SHUTDOWN)
goto unlock;
unix_state_unlock(sk);
if (!timeo) {
err = -EAGAIN;
break;
}
mutex_unlock(&u->iolock);
// 等待数据到来
timeo = unix_stream_data_wait(sk, timeo, last,
last_len, freezable);
if (signal_pending(current)) {
err = sock_intr_errno(timeo);
scm_destroy(&scm);
goto out;
}
mutex_lock(&u->iolock);
goto redo;
unlock:
unix_state_unlock(sk);
break;
}
// 循环处理 sk_buff 数据,找到要开始读取的 skb,并跳过已被读取的数据。skip 是需要跳过的数据字节数,它通过与每个 skb 的长度比较,决定是否需要跳过当前的 skb,直到找到需要读取的 skb。
while (skip >= unix_skb_len(skb)) {
skip -= unix_skb_len(skb);
last = skb;
last_len = skb->len;
skb = skb_peek_next(skb, &sk->sk_receive_queue);
if (!skb)
goto again;
}
unix_state_unlock(sk);
// 检查并设置消息发送者的凭据
if (check_creds) {
if (!unix_skb_scm_eq(skb, &scm))
break;
} else if (test_bit(SOCK_PASSCRED, &sock->flags) ||
test_bit(SOCK_PASSPIDFD, &sock->flags)) {
scm_set_cred(&scm, UNIXCB(skb).pid, UNIXCB(skb).uid, UNIXCB(skb).gid);
unix_set_secdata(&scm, skb);
check_creds = true;
}
// 将地址信息复制到消息中
if (state->msg && state->msg->msg_name) {
DECLARE_SOCKADDR(struct sockaddr_un *, sunaddr,
state->msg->msg_name);
unix_copy_addr(state->msg, skb->sk);
sunaddr = NULL;
}
// 确定本次要读取的数据量
chunk = min_t(unsigned int, unix_skb_len(skb) - skip, size);
skb_get(skb);
// recv_actor 是一个函数指针,用于将数据从 sk_buff 复制到用户空间的缓冲区中。
// recv_actor 会读取从偏移量 skip 开始的 chunk 字节的数据到指定的缓冲区,通常由 unix_stream_read_actor 指向的函数来完成。
chunk = state->recv_actor(skb, skip, chunk, state);
drop_skb = !unix_skb_len(skb);
consume_skb(skb);
if (chunk < 0) {
if (copied == 0)
copied = -EFAULT;
break;
}
copied += chunk;
size -= chunk;
if (drop_skb) {
err = 0;
break;
}
// 标记被读取的部分,将已读取的数据从缓冲区中标记为已消费,并调整偏移量,如果读取完毕则将 skb 从队列中移除并释放。
if (!(flags & MSG_PEEK)) {
UNIXCB(skb).consumed += chunk;
sk_peek_offset_bwd(sk, chunk);
if (UNIXCB(skb).fp) {
scm_stat_del(sk, skb);
unix_detach_fds(&scm, skb);
}
if (unix_skb_len(skb))
break;
skb_unlink(skb, &sk->sk_receive_queue);
consume_skb(skb);
if (scm.fp)
break;
} else {
if (UNIXCB(skb).fp)
unix_peek_fds(&scm, skb);
sk_peek_offset_fwd(sk, chunk);
if (UNIXCB(skb).fp)
break;
skip = 0;
last = skb;
last_len = skb->len;
unix_state_lock(sk);
skb = skb_peek_next(skb, &sk->sk_receive_queue);
if (skb)
goto again;
unix_state_unlock(sk);
break;
}
} while (size);
mutex_unlock(&u->iolock);
if (state->msg)
scm_recv_unix(sock, state->msg, &scm, flags);
else
scm_destroy(&scm);
out:
return copied ? : err;
}
几个套接字结构之间的区别如下表所示
| 名称 | 类型 | 位置 | 主要功能 |
|---|---|---|---|
socket |
用户空间结构 | 用户空间 | 由应用程序创建和操作的网络套接字接口,提供对外通信功能。 |
sock |
内核空间结构 | 内核空间 | 内核中的套接字表示,封装具体协议栈的实现,负责管理网络连接和数据传输。 |
unix_sock |
内核空间结构(sock的子类) |
内核空间 | 专用于 Unix 域套接字,存储特定于 Unix 域套接字的数据(如路径、地址等)。 |